2月21日午间, DeepSeek在社交平台X发文称,从下周开始,他们将开源5个代码库,以完全透明的方式与全球开发者社区分享他们的研究进展。并将这一计划定义为“Open Source Week”。
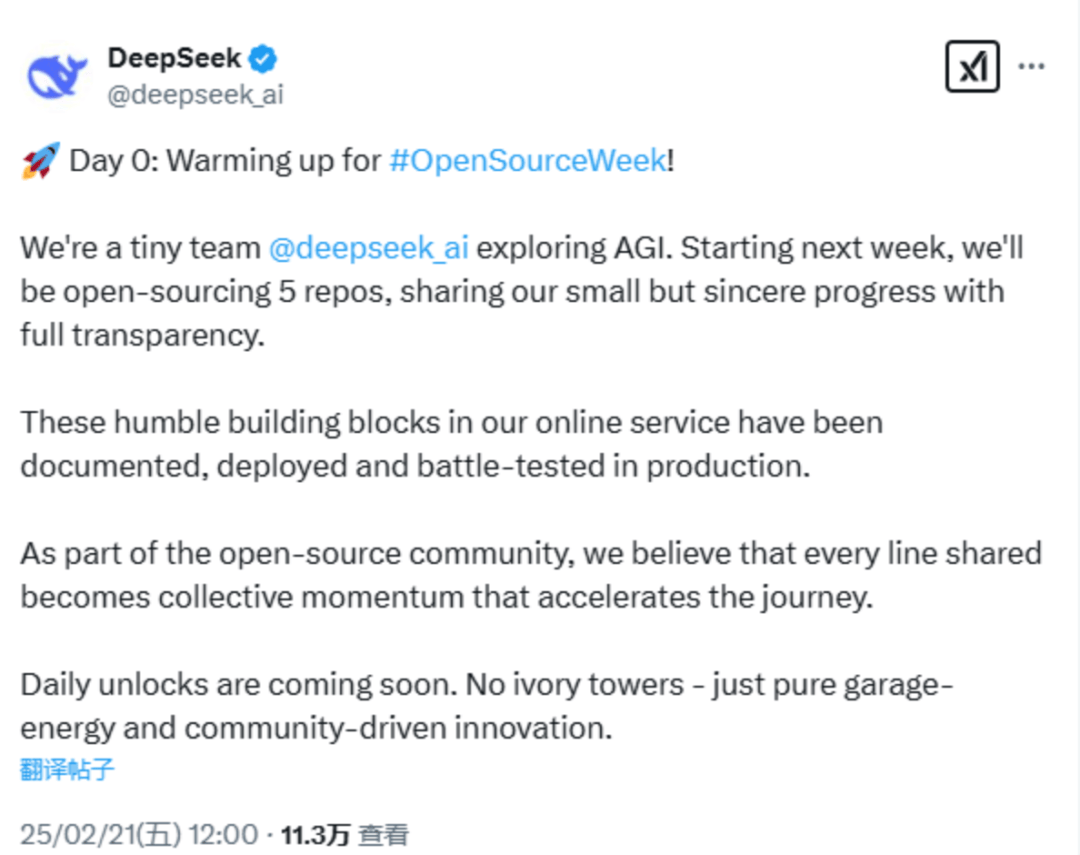
在最新发布的消息中,DeepSeek称:“我们是@deepseek_ai,一个致力于探索通用人工智能(AGI)的小团队。从下周开始,我们将开源5个代码库,以完全透明的方式分享我们虽小但真诚的进展。”
DeepSeek表示,即将开源的代码库是他们在线服务中的基础组件,且都经过了详细记录、部署和实战测试。
DeepSeek指出, 作为开源社区的一部分,他们相信分享的每一段代码都将汇聚成集体力量,推动行业加速前进。“每日解锁的内容即将上线。这里没有象牙塔,只有纯粹的车库创业精神和社区驱动的创新。”
公开信息显示,凭借低成本、高性能推理能力,DeepSeek持续火爆的同时,目前已有多个团队成功复现了其核心模型。例如Hugging Face的Open-R1、香港科技大学的simpleRL-reason、伯克利团队的TinyZero等。
另据数据分析平台QuestMobile最新数据,上线以来至2月9日,DeepSeek App的累计下载量已超1.1亿次,周活跃用户规模最高近9700万个。
全产业链能力是AI竞争关键
1月底,DeepSeek应用登顶苹果中美地区应用商店免费APP下载排行榜,超越了此前火爆出圈的ChatGPT等生成式AI产品,引来全球震动。微软、亚马逊、英伟达等全球科技巨头迅速接入DeepSeek模型,向开发者开放测试实验,国内政务、能源、通信、医院等多个领域及央企、互联网大厂也纷纷上线部署DeepSeek模型,产业生态加速构建。

DeepSeek火遍全球的原因在于成本低、性能高、开源开放。看性能,1月20日发布的DeepSeek-R1模型,性能接近OpenAI一个月前推出的推理模型o1,1月28日发布的开源多模态人工智能模型Janus-Pro,模型准确率超过OpenAI DALL-E3大模型。看价格,据测算,DeepSeek-V3模型的训练成本仅为OpenAI同性能模型GPT-4的十分之一,DeepSeek-R1仅用OpenAI o1模型3%至5%的成本就达到同等性能,推理方面OpenAI o1模型的使用成本接近DeepSeek-R1模型的30倍。更重要的是,DeepSeek选择开源其大模型产品,支持免费使用、任意修改和衍生开发等,大大降低了使用门槛,因而迅速占领市场。
DeepSeek的成功表明全产业链能力是产业竞争的关键。近年来,中美作为人工智能领域的第一梯队,在技术研发、产业应用、人才与数据等方面全方位比拼,各有优势。尽管我国人工智能在部分底层技术、核心算法、高端芯片、关键基础软件等方面弱于美国,但具备完整产业链优势。DeepSeek打破了“堆算力、拼数据”的传统路径,降低对算力和高性能芯片的依赖,再次证明,全产业体系布局和系统协同优化能弥补不足,走出不同的人工智能创新路径。
丰富的应用场景也是中国发展人工智能的优势。我国具有工业门类全、人口基数大、市场需求多、互联网应用深入等优势,为人工智能提供了多元化应用场景,催生更多“杀手级”应用和高价值场景。此前,我国行业大模型已深度赋能电子信息、医疗、交通等领域,形成上百种应用模式。 DeepSeek模型发布后,华为、腾讯、三大电信运营商等龙头企业以及政务、教育、能源、保险等领域已迅速接入,不仅为其提供了更好的算力方案和配套环境,也通过多场景、多产品应用推动DeepSeek模型不断完善优化。
开源开放将加速技术创新与生态构建。开源的本质在于开放共享、协作创新,集众智、采众长,突破创新的时空边界,缩短产业转化的创新周期。曾经,安卓因为开源迅速成为全球市场占有率最高的移动操作系统。如今,开源也有望重塑人工智能行业格局。 受DeepSeek影响,国内外多家人工智能大模型从原本的闭源转向开源。当前,我国开源模型领跑全球,与闭源模型能力差距逐步缩小,高性价比的开源大模型已成为人工智能产业发展的重要技术底座。我国是世界最大的开源应用市场,拥有全球最大规模的开发者群体,将与全球开发者一同为DeepSeek等开源大模型添砖加瓦,推动我国人工智能产业创新发展。

人工智能技术发展日新月异,下定论还为时过早。但DeepSeek再次让我们坚定,着眼未来,我们既要在前沿技术上对标领先水平,也要推动大模型应用快速落地,发挥产业生态的竞争优势,才有望在人工智能领域缩小差距甚至赶超领先。
来源:中国经济网微信综合经济日报(作者 黄鑫)、中国基金报微信
监制: 张益勇审核:杜秀萍
编辑:王俊杰 校对:刘莉返回搜狐,查看更多