大洋彼岸的 OpenAI 迟迟没有发布 GPT-5,一度让业界怀疑 Scaling Law是否已经失效。然而,国内多个团队却接连推出重磅 AI 大模型,用事实证明 Scaling 依然有效,只不过并不是无脑堆硬件、堆算力。
Kimi k1.5的这次推出的大模型就是以推理能力见长的模型。
不知道你们有没有注意到Recipe这个词,在Kimi k1.5的技术报告提到了好多次,它的意思是「菜谱」,相当于说把一道菜需要的原材料、炊具以及注意事项都明明白白告诉你了。
技术报告链接:
https://github.com/MoonshotAI/Kimi-k1.5/blob/main/Kimi_k1.5.pdf
可以说,一向闭源的Kimi这次的技术报告可以理解为「半开源」,就像把西红柿鸡蛋的做法一步步的列出来,你模仿它的方法即可,唯一不同的就是具体的操作差异。
比如你的火力大一点儿,锅的材质不同等等,并且Kimi k1.5的性能在好几个方面的性能都已经事实上的超过了OpenAI o1满血版,可以说是含金量非常高的一次「半开源」。
特别是OpenAI o3,也就是在FrontierMath这个非常难的数学测试集上达到了变态成绩后的几周,被曝出暗中资助了这个比赛的丑闻。

如果o3是靠在数据集和答案上预训练出来的,那么它这种既当运动员也当裁判员的操作,也才拿到了25%左右的正确率,这只能证明o3仅是o1的特殊微调版,只是用来维持OpenAI纸面荣誉的工具。
那Kimi k1.5的含金量就直线上升了,long CoT在Math数学推理,Code编程能力以及Vision视觉多模态上的表现,4/6超过了最强的o1正式版模型。
Kimi k1.5还用了Long2short的方法,将Long CoT的能力迁移到Short CoT上,也在大多数的任务上达到了SOTA的水平,最牛的是在AIME的Pass@1实验中,效果远超其他几家(第一个子图蓝色的Kimi独树一帜)。

特别是Long2short之后迭代出来的几个short CoT,在下面这两个数学数据集上的性能甚至超过了long CoT,可见CoT可以深挖甚至scaling的地方还有很多。

这些数据基本上表明了OpenAI o1满血版的性能全面在Kimi k1.5上实现,更重要的是Kimi K系列的快速迭代能力,从初代 Kimi k0 math 到Top级别的 Kimi 1.5,就俩月多点,直接数学偏科到全科专精。
其中第一个长上下文是最近发布的几个大模型的共性,因为初代LLM的思路简单直接,就是一问一答,单步操作;
但是后来发现这样的单步操作对于比较复杂的问题,比如数学物理等需要更多逻辑思考且一步完不成的任务,就需要思维链(CoT)这样的技术,相比起初代LLM,推理大模型可以将复杂的任务分成简单的单步任务进行。
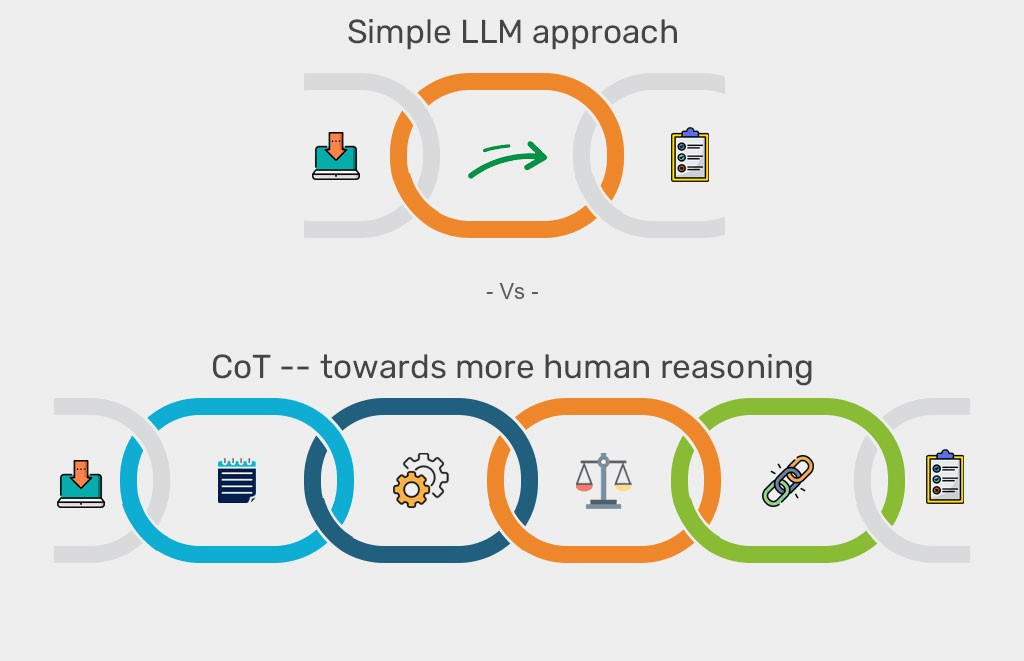
这样的好处很直接,不过缺点也很明显,那就是这些思考过程明显是需要更多的“记忆力”,换到LLM大模型领域就是上下文长度了,理论上越长越好,最近发布的MiniMax-01就把上下文长度记录拉到了400万。
Kimi k1.5并没有在极限上下文上做文章,而是将long context长度定为128K,然后用Partial Rollout的方法重复利用历史记录,而不是重新生成,这样的策略从结果上表明非常有效。

再加上如果用过OpenAI o1的话,很多简单的问题o1会出现过度思考(overthinking)的现象,其实这也是一种对于计算能力的浪费以及策略不够优化的表现。
菜谱也提到了这个点,他们采用了长度惩罚(Length Penalty)的措施,倒逼大模型跟人类对齐,毕竟人类不会对一个简单问题思考6分钟。
